-
New RubyOSA Website Apr 12, 2007
RubyOSA now has a new website! The new site features updated information from Laurent and I, including a new guide. Over the coming weeks, we’ll continue to expand and improve its content.

Please let us know what you think about it!
Update: This post was featured on Laurent Sansonetti’s diary.
-
OSA::ObjectSpecifierList#every Mar 26, 2007
For those of you who aren’t yet on the RubyOSA list (you should be), Laurent just committed a nice new feature to
OSA::ObjectSpecifierList. It’s actually been there since last week, in the form of somemethod_missinghackery, but we finally decided to take that out and call it#every.Sometimes you need to collect an attribute from every object in the specifier list. Normally, you’d do something like this:
names = OSA.app('iCal').calendars.collect { |c| c.name }Symbol#to_proc fans use the convenient form:
names = OSA.app('iCal').calendars.collect(&:name)Now,
OSA::ObjectSpecifierListalso has the#everymethod:names = OSA.app('iCal').calendars.every(:name)The difference is subtle but
#everywill fetch all of the attributes in a single Apple Event, something not possible when iterating over each item in the collection. For most purposes this is not important but it is a nice feature that could make a difference on larger collections.This feature is currently in the RubyOSA trunk and will appear in the next stable release (coming soon).
Update: RubyOSA 4.0 has been released and includes this feature!
-
DRY up testing in Rails with Autotest Mar 23, 2007
As Rails developers, we’ve been trained hard to test early and test often. We are also acutely aware of the DRY principle (Don’t Repeat Yourself). However, these ideas don’t quite agree in Rails because in our test-code-test cycle, we’re constantly typing
rakeevery time we need to run our tests.Autotest will DRY up your testing by running your tests automatically whenever your files change. In this article, we’ll explore Autotest:
- Installation
- Starting Autotest
- Stopping Autotest
- Autotest Plugins
- Coloring with RedGreen
- Notifications
- Next Steps
Installation
Autotest is a smart little program included in the ZenTest bundle of goodies. To install it, you’ll just need to install the gem for ZenTest.
gem install ZenTest
Depending on how your system is set up, you might need to run this as the root user or through
sudo.Starting Autotest
Running Autotest is as simple as running rake. First, change to the root directory of your Rails project. This is the directory that has
Rakefile,app/,config/, etc. Next, run theautotestcommand:$ autotest
Autotest will discover that it is running inside a Rails project and your tests will run just as they do with
rake(or the wordierrake test).After your tests run, Autotest will not exit back to the shell prompt. It will then sit and poll your files. When it notices files that change, it will run the tests for only the files that you’ve changed! It will do this continuously until you stop it.
Stopping Autotest
Pressing
Control-Conce will run your entire test suite again.Pressing
Control-Ctwice in quick succession will exit Autotest back to the shell prompt.Autotest Plugins
Autotest includes a plugin mechanism that allows plugins to monitor different aspects of the testing lifecycle. Autotest includes a number of useful plugins out of the box.
In the next sections, we’ll see how to activate the plugins and what functionality they provide.
Coloring with RedGreen
One of the problems of testing under
rakeandautotestis that a lot of output can be generated and when looking at the results, you sometimes have to filter out the normal output to see the failures.RedGreen is a simple Autotest plugin that solves this problem by coloring the summary lines of the test output either red or green to indicate whether the tests passed or failed:
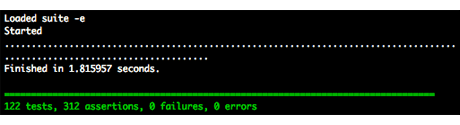
Autotest automatically looks for a dotfile (
.autotest) when it is started. This file may be in your Rails project directory or in your home directory where it will be used by all projects.To install RedGreen or any other plugin, create the
.autotestfile with a simplerequireto load the plugin:# .autotest require 'autotest/redgreen'
That’s it! When you run autotest again, the plugin will be automatically loaded and your test output colored.
Notifications
Autotest also comes with the plugins
growl,snarl, andkdenotify. Each are installed the same way as shown above, simply add the require line to your.autotestfile. These allow Autotest to communicate each respective notification system.
Using one of these can be useful when running autotest in the background or in a minimized window. The screenshot above shows a Growl pop-up notification from Autotest under Mac OS X.
Note that for Autotest to send notifications to Growl, the
growlnotifyutility must be installed. This comes in theExtras/directory of the Growl disk image.Next Steps
Autotest isn’t limited to plugins shown here. There are a number of other useful plugins you can explore and more are added all the time. The plugins can be found in
/path/to/your/gems/ZenTest-x.x.x/lib/autotest.While Autotest can be an invaluable tool when testing Rails applications, it isn’t limited to Rails at all. Autotest can be used with an Ruby project that follows some simple conventions.
Visit the Autotest section of the ZenTest RDoc to learn about this, writing plugins, and more.
-
Rails Logging Tips Feb 24, 2007
In this article, we’ll take a look at how to use the logging facilities built into Rails and then share a few tips:
- Accessing the Rails Logger
- Log Levels
- Filtering Sensitive Parameters
- Creating Audit Logs
- ActiveRecord Logging to the Console
- ActionController Logging to the Console
- Firebug Console
Accessing the Rails Logger
Rails automatically sets up logging to a file in the
log/directory using Logger from the Ruby Standard Library. Do not confuse this with Log4r, a completely different library. The logfile will be named corresponding to your environment, e.g.log/development.log.To log a message from either a controller or a model, access the Rails logger instance with the
loggermethod:class HomeController < ActionController::Base def index logger.info 'informational message' end endFrom outside a controller or model, you can pass the logger instance or access it with the constant
RAILS_DEFAULT_LOGGER.Log Levels
In the snippet above, a message is logged at the INFO level by calling a method of the same name (
info).The levels available on the logger are (in ascending order):
debug,info,warn,error, andfatal.Ruby's Logger supports masking levels so the types of messages recorded in the log can be controlled. By default, Rails will log all levels (
debugand higher) in every environment except production. In the production environment, it will only loginfoand higher. This behavior can be changed in the configuration for each environment.Filtering Sensitive Parameters
When Rails receives a request, ActionController logs the request parameters. This is very handy for debugging but sometimes it's not desirable to have certain parameters, such as passwords, stored as plain text in the log.
Rails 1.2 introduced the
filter_parameter_loggingclass method to remedy this:class ApplicationController < ActionController::Base filter_parameter_logging :password end
The above will cause any parameter name matching
/password/ito have its value replaced with[FILTERED]in the log. To filter multiple parameters, simply add them as extra arguments tofilter_parameter_loggingby separating them with commas. For other uses offilter_parameter_logging, see the ActionController documentation.Note: it's important to remember that
filter_parameter_loggingwill only filter ActionController request information. The parameters could still appear in any SQL queries being logged by ActiveRecord. However, SQL queries are not logged in the production environment by default.Creating Audit Logs
Sometimes logging is required but putting the messages in the Rails log isn't desirable. One such case is when keeping a separate logfile for auditing is a business requirement.
To create an audit log, simply create a new instance of
Loggerand pass it aFileinstance for your own logfile.One possible source of confusion is the formatting of the log message due to a patch Rails makes to
Logger. This can be seen when usingirbas opposed toscript/console:$ irb irb(main):001:0> require 'logger' => true irb(main):002:0> Logger.new(STDOUT).info('message') I, [2007-02-24T09:45:51.236763 #557] INFO -- : message$ script/console Loading development environment. >> Logger.new(STDOUT).info('message') messageAs you can see, the message formatting is lost when run in the Rails environment. To format a log message when using Rails, create your own Logger subclass and implement the
format_messagemethod:class AuditLogger < Logger def format_message(severity, timestamp, progname, msg) "#{timestamp.to_formatted_s(:db)} #{severity} #{msg}\n" end endTo use the new
AuditLogger, instantiate it with aFileinstance:logfile = File.open('/path/to/audit.log', 'a') audit_log = AuditLogger.new(logfile)Your new log is now ready to use by calling methods on it like
audit_log.info 'message'.One important point to remember is that the
logfileobject does not implicitly flush to the file by default. This means that your code must calllogfile.flushfor the data to be written out. Alternatively, you can setlogfile.sync = trueto turn on implicit flushing.ActiveRecord Logging on the Console
When debugging your applications with
script/console, it can be very useful to see the SQL output of your ActiveRecord queries. One way to do this is to usetail -fon your logfile.However, this isn't very convenient and shows all other log information as well. An easier way that can be done directly from script/console is to enter this line:
ActiveRecord::Base.logger = Logger.new(STDOUT)
This will cause the queries to be displayed immediately on the console as you interact with your ActiveRecord objects with method calls like
Article.find :all.ActionController Logging on the Console
Just like with ActiveRecord above, you can also redirect ActionController's log output to the console when using
script/console:ActionController::Base.logger = Logger.new(STDOUT)
You can then observe ActionController activities when using using using the app object on the console, such as app.get '/'. For a brief tutorial on using app, see this post on Mike Clark's weblog.
Firebug Console
Firebug is a popular extension for the Firefox browser that provides a number of useful capabilities, with a Javascript console being among them. The console is accessed by
console.log('message')in Javascript.This means that any Rails view emitting this little Javascript call between
<script>tags can write to the Firebug console.It also means that any RJS template can write to the Firebug console for debugging:
page.call 'console.log', 'informational message'
This can be very useful for logging debug information during AJAX requests where a popup from
alert()isn't desirable. -
Pragmatic Studio Training Oct 14, 2006
 Earlier this week, I attended the Pragmatic Studio Rails Training in Dallas, TX. The course is taught by Dave Thomas and Mike Clark. Both are talented, motivational trainers and the course material is top notch.
Earlier this week, I attended the Pragmatic Studio Rails Training in Dallas, TX. The course is taught by Dave Thomas and Mike Clark. Both are talented, motivational trainers and the course material is top notch.As I’m more used to sitting on the trainers’ side of the table, it was obvious to me they’d taken a great deal of care to develop the material. Having read the Agile Web Development book, I thought the course did a great job of tying those concepts together and filling in the gaps left by the print.
Since I’ve already built several Rails applications, I took the training with the intention of solidifying my foundation of Rails and Ruby fundamentals. I feel that I definitely achieved that goal. While the course was suitable for most beginners, there was enough sprinkling of tricks, idioms, opinion, and humor to keep participants of most skill levels engaged.
The training was highly oriented towards exercises and labs. For the most part, everyone was able to work at their own pace. Novices got the help they needed while more experienced users didn’t get bored. I was also pleased that the course material was current and at least touched on some of the newer features in Rails such as ActiveResource and more advanced topics like deploying with Capistrano.
Overall, it was a great experience and I’m looking forward to attending more training courses offered by Pragmatic Studio in the future.
-
Custom Rescue Templates for Rails Oct 9, 2006
Ruby on Rails provides a nice feature for development that displays neatly formatted error screens when an exception is raised. This screen is very convenient because it can usually show the line number where the error occurred, different views of the backtrace, and other useful troubleshooting data including the environment, session, and request/response objects. Having this information is not only useful but provides a feeling of stability and more graceful error handling compared to something like PHP’s raw errors (enhanceable by xdebug).
The default Ruby on Rails error screens are very functional but are also quite plain. Some Rails developers, particularly those working on teams, may wish to tailor them to provide consistent styling with their application or to display additional application-specific information for the development environment.
The Rails error screens are generated by views bundled inside ActionController called rescue templates. David recently committed my first patch to Edge Rails in changeset 5243. Now, creating your own custom rescue templates is very straightforward.
Begin by copying the default rescue templates to a new directory under
app/viewsin your Rails project. I recommendapp/views/rescues. The rescue templates are found in ActionController, which is undervendor/railsfor projects on Edge Rails or that have frozen Rails.$ mkdir app/views/rescues $ cp vendor/rails/actionpack/lib/action_controller/templates/rescues/* \ app/views/rescuesNext, add the following snippet to your
ApplicationController:protected def rescues_path(template_name) "#{template_root}/rescues/#{template_name}.rhtml" endThe templates will now be taken from your
app/views/rescuesdirectory and can be modified to taste. To test, browse to any action that willraisean exception.As of Rails 1.1.6, the instructions above will only work on Edge Rails but will work in the next stable version. See the ticket for more information to patch 1.1.6 and earlier versions.
You are encouraged to read the API documentation for
ActionController::Rescueto understand how and when the rescue templates are rendered. It is important to note that for security, the rescue templates should never be shown to the public and thus only ever rendered when a request is considered local.Update: This tutorial was featured on Riding Rails, the Ruby on Rails weblog.
Update: These instructions work with the stable release of Rails since 1.2.
Update: As of changeset 6120,
template_rootis nowview_paths.first -
Upcoming Talks Sep 11, 2006
The nice folks behind the DC PHP Conference asked me to put out a note to let you know I’ll be speaking there, so here’s a bit about the talks I’ll be giving and other events I’ll be attending in the next couple of months:
DC PHP Conference (Oct 18-20)
- PHP Intranet Web Services is a new talk that is geared to fit into the conference’s theme of “integration with the federal government”. PHP is an excellent glue language for integrating web services and legacy applications on intranets and there are a host of libraries available to help. We’ll explore some of these options and talk about the unique aspects of developing PHP-based services behind corporate firewalls.
- Getting Started with Zend Framework will give developers a jumpstart on developing with the Zend Framework. A brief introduction will include installation, an architectural overview, comparing it with alternatives, and explaining its process and online resources. We’ll then dive right into some of the more useful components through examples with sample code. I’ve been around the Zend Framework longer than most so feel free to bring all of your questions for Q&A and code for possible hacking sprints later.
Zend/PHP Conference 2006 (Oct 30 – Nov 2)
- Best Practices of PHP Development will be an extensive three-hour tutorial session. Matthew and I had such a good time speaking at the last Zend conference that we’re doing it together again this year with a new tutorial session. We’ve both been working as professional PHP developers for many years and this is our chance to share some of the PHP development and deployment tricks we’ve learned along the way.
Other Events
Since starting my own consulting business, I’ve also been having a great time doing quite a bit of Ruby on Rails development in addition to my usual Python and PHP programming and training. As I dip into Ruby more, I’ll be attending the Pragmatic Studio (Oct 9-11) and also the Rails Edge Conference (Nov 16-18).
If you’re headed to any of these events, contact me if you’d like to meet up or if you have any requests for the talks.
-
Silicon Valley Ruby Conference Apr 28, 2006
Thanks to the nice folks at Zend, I attended the Silicon Valley Ruby Conference on April 22nd and 23rd. This was a first-year event hosted by SDForum.
Despite being a long-time Python programmer and now working at “the PHP company”, my interest in Ruby has been increasing exponentially over the last few months. This began some time ago when Zend asked me to study Ruby on Rails. Since then, my interest in Rails has exploded and Rails has quickly become my favorite platform for web applications. As my proficiency in Rails has increased, it has fueled my interest in the Ruby language. Ruby itself is most certainly the best feature of Rails.
One of the best discoveries of the conference was seeing Ryan Davis’ presentation of Autotest. This is a neat little program that continuously scans your project files and reruns your tests when your files change. After only a few days, it now runs almost continuously on my machine.
Jason Hoffman gave an excellent presentation on scaling Rails. The “is Rails scalable?” question was most certainly the loudest background noise heard throughout the conference. Jason’s presentation was informative, entertaining, and helped squelch a lot of the FUD.
Building Domain Specific Languages (DSLs) with Ruby was the most prevalent topic in the presentations. Both Chad Fowler and Joe O’Brien spoke on the topic in good detail and I learned some new techniques for building DSLs. David Pollack presented a talk called on “Metaprogramming, Building Class on the Fly” that also had a lot of discussion about DSLs. Unfortunately, I think that one missed the mark because it went into preprocessing XML files and other odd topics. For me, Ruby’s power lies in using its rich and expressive syntax to build DSLs in Ruby itself.
The Silicon Valley Ruby Conference was my first real introduction to the Ruby community and I had a blast. Everyone I talked with at the conference was smart, friendly, and grooving on Ruby as much as I am. I’ll certainly be attending future Ruby events whenever I can.
Update: I’ve written an article on Autotest, which has since become one of my favorite utilities.
Update: The second annual Silicon Valley Ruby Conference has been announced. I’ll be there!
-
MashupCamp Feb 23, 2006
Earlier this week, I spent two days at MashupCamp. This great event was held at the Computer History Museum in Mountain View, California.
Mashups are an interesting topic. “Mashup” is one of those terms like “Web 2.0” that’s trendy and really hard to define in any concrete terms. Basically, mashups are taking two or more web service APIs (or data somehow gleamed from the web) and then building a useful application by combining them.
The caliber of developers that attended was top notch and this could easily be seen by the great apps that were demonstrated. These were the kind of folks that know XML inside and out, know everything annoying about SOAP headers, know XHTML strict better than HTML 4, and can tell you the method signatures of the services they use from memory. Every developer that I talked with had experience with at least two scripting languages, usually more. It was a great crowd with some very smart and talented people in attendance.
Mashups themselves tend to get put together very quickly. Sometimes people get an idea and implement a mashup in a few hours or a few days. It was great to be around so many developers who really grok the newest web technologies and know the fastest ways to develop applications to take advantage of them. So, what were they using to get things done fast? Besides the mashups themselves, that’s what I was interested in learning about.
It turns out these developers were really pragmatic. They use what works and gets their job done the fastest without getting in the way — even if that means Perl. I don’t mean Catalyst or any other kind of fancy frameworkish thing, I mean straight Perl CGI. If you read the blogs these days, you’d think Perl is almost dead for web applications. I counted four mashups using Perl in some way. The most common application was backend processing but I saw one using it on the frontend as well.
Three mashups that I saw were using Python. One of them was built on the Twisted asynchronous framework. I’ve done some work with Medusa but haven’t worked on a project needing all the power of Twisted yet. It certainly looks impressive. Another Python mashup was the excellent chicagocrime.org website, built on the Django framework by its co-creator Adrian Holovaty. A lot of people I talked with at MashupCamp were interested in Python, especially at the Googleplex where I attended an afterparty (thanks, Adam!). Several Googlers told me Python is Google’s standard scripting language and were quick to mention that Google recently picked up Python creator Guido van Rossum. Of course, everyone reading his blog already knows that.
Ruby has a nice buzz going these days and it wasn’t surprising that it made a showing as well. I counted one mashup using it, powered by Ruby-on-Rails, although it was sort of a joke by a PHP 5 developer (the author of TagCloud). I heard that there was another Ruby-based mashup there but to my knowledge it wasn’t demoed. Coming from more of a Python background, I spent quite a bit of time with a couple of the Ruby developers at the conference to see what they liked best about the language and why they’d picked it over Python. I’m not sure that they drew any significant conclusions but they were down-to-earth and really nice guys. One of the Ruby users was also telling me about Nitro and seemed particularly enthusiastic about Og. A company called Rubyred Labs brought some nice grapefruit.
ASP.net had a presence with one mashup using it. As with the Zend PHP Conference, I did get some nice freebies from Microsoft and noticed all the coffee cups said “Microsoft” on them. The coffee wasn’t bad, either. Visual Studio was given out as one of the prizes. I’ve already got my copy and you can download Express online.
Java didn’t make a showing as far as I saw, although Stephen O’Grady noted one that I apparently missed. However, there was an appearance by Johnathan Schwartz who gave away a T2000 server.
PHP was unquestionably the language of choice for developers at MashupCamp. I counted thirteen mashups using it. I made a point to talk to as many PHP developers as I could and nearly everyone had moved to PHP 5, although some were still supporting customers with legacy PHP 4 code. I believe nine out of the thirteen mashups powered by PHP were on PHP 5, with at least one more in transition. Most of the mashups were built within the past few months, or in many cases, the past few weeks. Everyone seemed very excited about PHP 5 in general.
Amongst all of the hi-tech showings at this event, I have to say that the highlight for me was definitely meeting Bob Frankston. Bob, together with Dan Bricklin, developed the world’s first spreadsheet for microcomputers: Visicalc. This might be showing my age but it was truly an honor to meet this tech luminary and chat with him about the first generation of microcomputers, the 6502 microprocessor, Commodore computers, and everything in between. Thanks, Bob. I won’t soon forget it.
All in all, it was a great event and I’m looking forward to the next one.
-
Symfony Templates and Ruby’s ERb Feb 19, 2006
After hearing the podcast, I went over to the Symfony website to check it out. I haven’t downloaded Symfony yet but I did watch this screencast. One thing that I think Symfony gets right is that it appears to use partitioned PHP code for its templates, in the spirit of Paul‘s Savant system. Putting all the “Smarty vs. Savant”-type arguments aside, the resulting templates in Symfony are nice and look very much like ERb (.rhtml) as it is used by Ruby-on-Rails. I think the ERb templates are a bit cleaner. However, it doesn’t have to stay that way.
In Ruby, instance variables are accessed with
@var_name. This is the same asself.var_namein Python or$this->var_namein PHP. If the template’s variables are scoped as instance variables of a class such as in Savant, andshort_open_tagis disabled, the resulting PHP syntax can be a bit unwieldy:var_name ?>
Compare this to the succinct but equally powerful ERb:
<%= @var_name %>
I noticed in the Symfony demo that there is no separation of scope between variables passed to the template from the controller and local variables in the template. In the screencast,
$productsin the template comes from the controller and is indistinguishable from the local variables$idand$title. I’d like to see them scoped properly ($this->products) but I can certainly understand why they did it this way. Using$this->in the template everywhere quickly gets messy.One solution to this problem is to enable short_open_tags and then give the nod to Ruby by overloading PHP’s silence operator (
@) to $this-> in the templates. This gives a very similar syntax to ERb:Using the silence operator in this way won’t break syntax highlighting in the IDEs, since this is legal PHP syntax on its own. The silence operator would not normally prefix a dollar sign, so keeping the dollar allows us to distinguish between normal code that should be silenced and when the operator is overloaded to
$this->. Templates should never be doing operations that need to be silenced anyway.The syntax shown above is much shorter and more convenient but there appear to be two problems with this solution. First, relying on
short_open_tagis a beginner’s mistake in PHP since it’s not enabled on all installations. Second, it’s not practical on most installations to install an extension to do this overloading.Fortunately, there is an easy solution to both of these problems. At some point, the template engine must include() the templates for PHP to execute them. A stream wrapper can be registered to rewrite the
@$into$this->and also expand short tags ifshort_open_tagis not enabled. The result is a short snippet of pure PHP code that gives this syntax and should also run on the majority of installations.Here’s the proof of concept (PHP 5).
Search
Links
Contact
Categories
Articles
- Applying Ruby's Blocks
- Deploying on Phusion Passenger
- Fail Early
- Ruby Block Scope
- PHP, Meet YAML
- Useful Perlisms in Ruby
- Wrap PHP Functions for Testability
- DRY up Rails testing with Autotest
- Rails Logging Tips
- Easier XML-RPC for PHP 5
- Introducing Zend Framework
- Custom Rescue Templates
- X-10 FireCracker CM17A Control
- Reading the Sharp GP2D02
- Build a 6504-based Microcomputer